|
I am a senior research scientist at the MBZUAI Institute of Foundation Models. I study computer vision. I completed my PhD in the department of Computer Science at the University of Maryland (UMD), advised by Professor Abhinav Shrivastava. The highlight of my PhD was when we organized the workshop on Implicit Neural Representation for Video at CVPR 2024. I also enjoyed opportunities to work as an intern at Amazon, SRI, and NVIDIA, on applications including recommendation, video retrieval, and efficiency for diffusion image generation. During my PhD, I worked on a lot of different things, typically all falling under the umbrella of "representation learning" (if we use the term very loosely). I worked on video compression, efficient image generation, and image recognition. Now, I mainly focus on building world models, but I am also still interested in efficiency, compression, and INR. Please reach out if you are interested in collaborating. Email / CV / Google Scholar |

|
|
World models, video generation, unified generation and understanding. I still like INR too, though. |
|
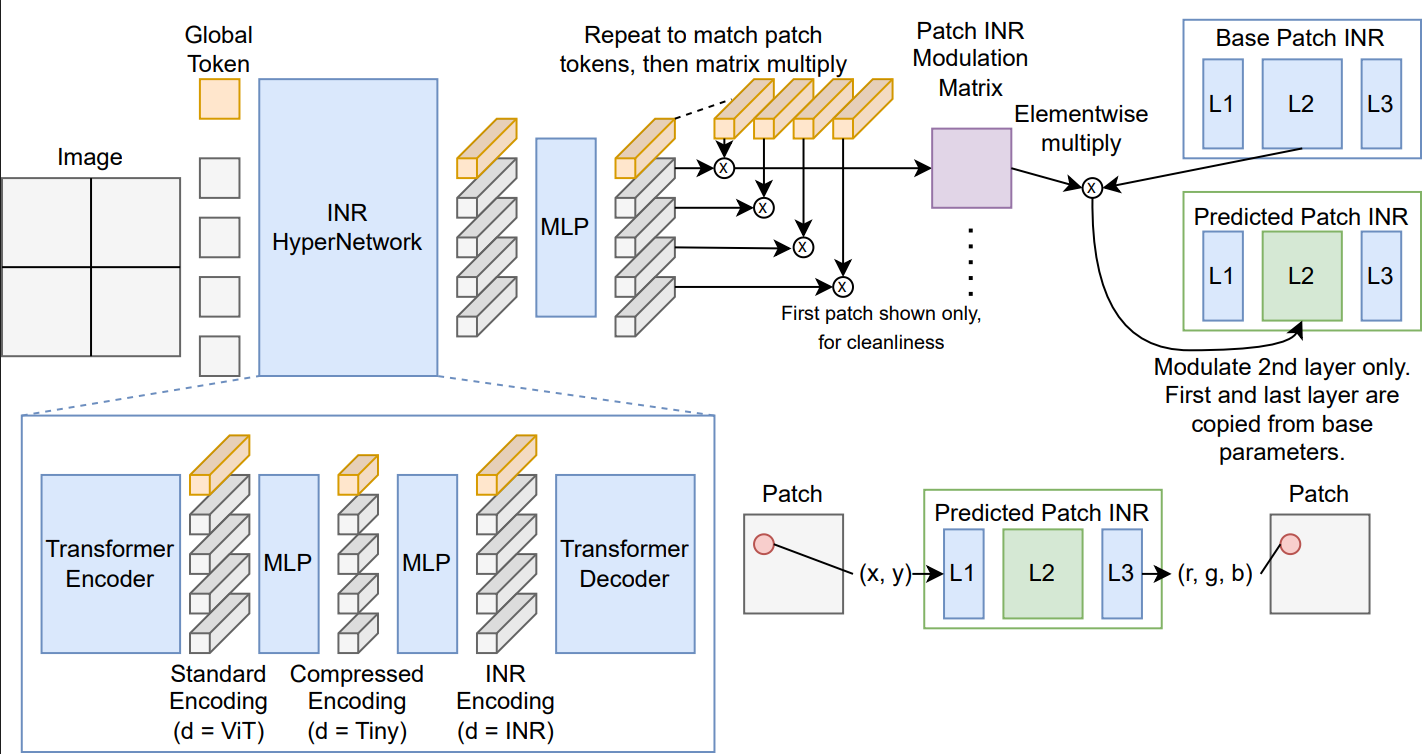
Matthew Gwilliam, Xiao Wang, Xuefeng Hu, Zhenheng Yang European Conference on Computer Vision (ECCV), 2026 Paper | Models | Code A representation learning model that learns both standard and compressed (24x-96x smaller) latent representations of images. Embeddings are useful not just for classification, but also segmentation, depth prediction, reconstruction, and even generation. |
|
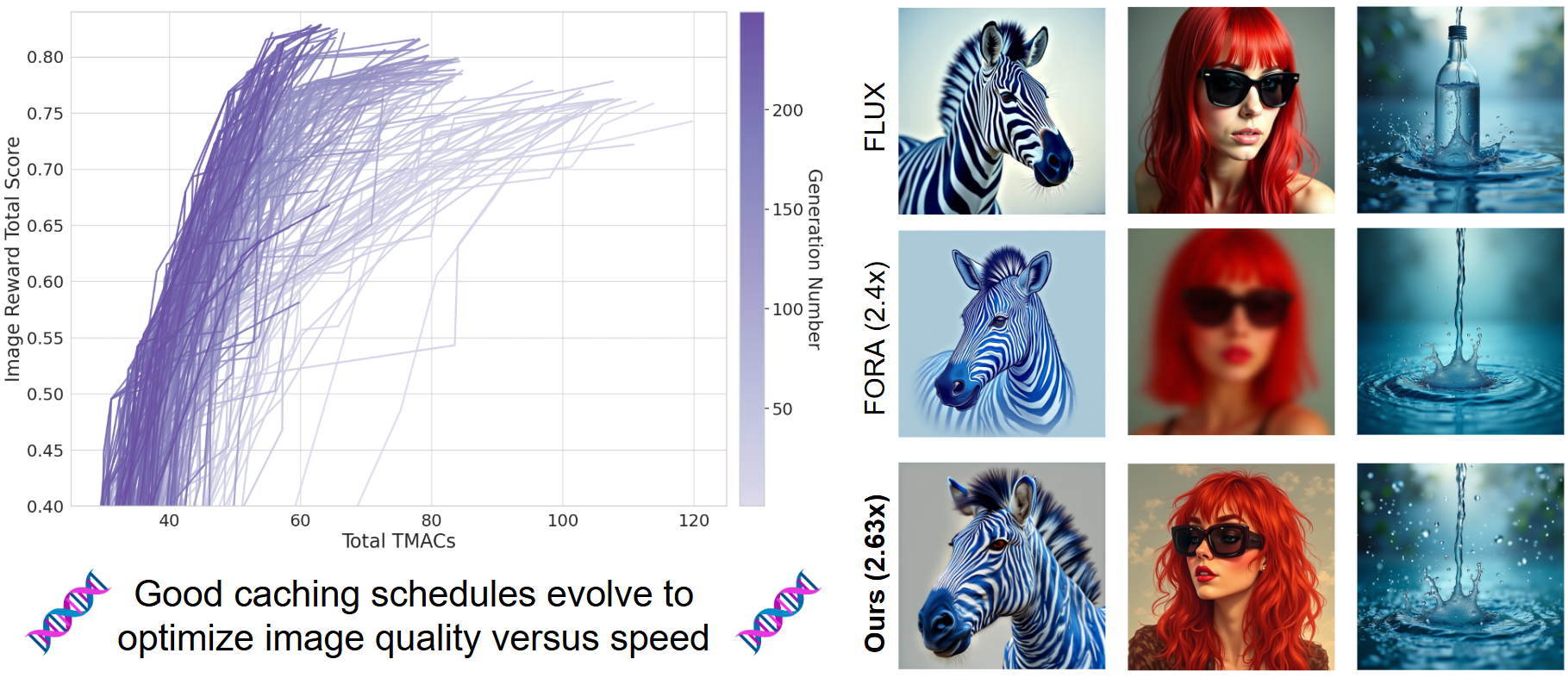
Anirud Aggarwal, Abhinav Shrivastava, Matthew Gwilliam International Conference on Learning Representations (ICLR), 2026 Project Page | Paper | Code A genetic algorithm that learns an optimal configuration for caching and reusing the inference computations of any given pretrained diffusion model during the expensive iterative denoising process. Our ECAD finds schedules that aggressively speed up the image generation process by >2x. |
|
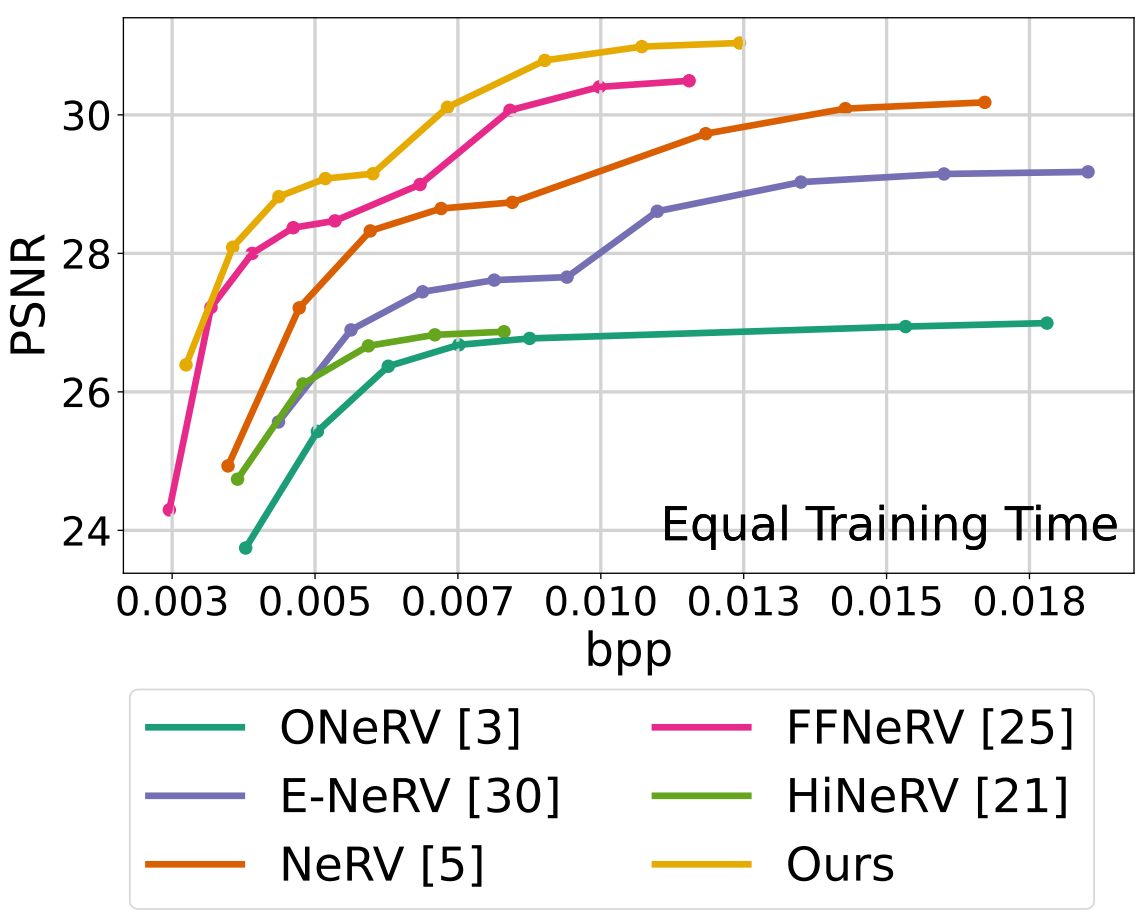
Matthew Gwilliam, Roy Zhang, Namitha Padmanabhan, Hongyang Du, Abhinav Shrivastava IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2026 Project Page | Paper | Code Disentangling the design space of implicit neural representations for video compression to understand the interactions between components from different methods. We reassemble these components in a way that not only maximizes the size-quality tradeoff, but also allows for optimal fast training times. |
|
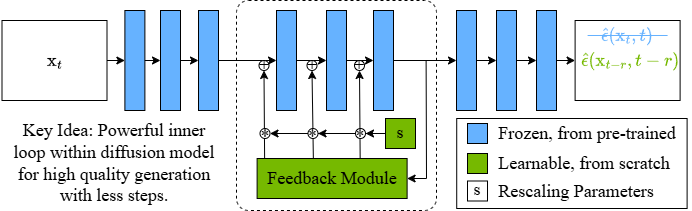
Matthew Gwilliam, Han Cai, Di Wu, Abhinav Shrivastava, Zhiyu Cheng Preprint only, 2025 Project Page | Paper A novel lightweight feedback mechanism that creates a powerful inner loop within a diffusion model, allowing for more powerful diffusion denoising steps. We can use few powerful feedback steps to accomplish the job of many normal steps, allowing for higher image quailty in less inference time. |

|
Matthew Gwilliam, Michael Cogswell, Meng Ye, Karan Sikka, Abhinav Shrivastava, Ajay Divakaran IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025 Project Page | Paper Propose an alternative to paragraphs for long video retrieval, specifically, the 10k Words problem: every video should be able to be matched with any valid description, so we generate many descriptions for every video (for 3 long video datasets), evaluate accordingly, and introduce novel finetuning for better performance. |
|
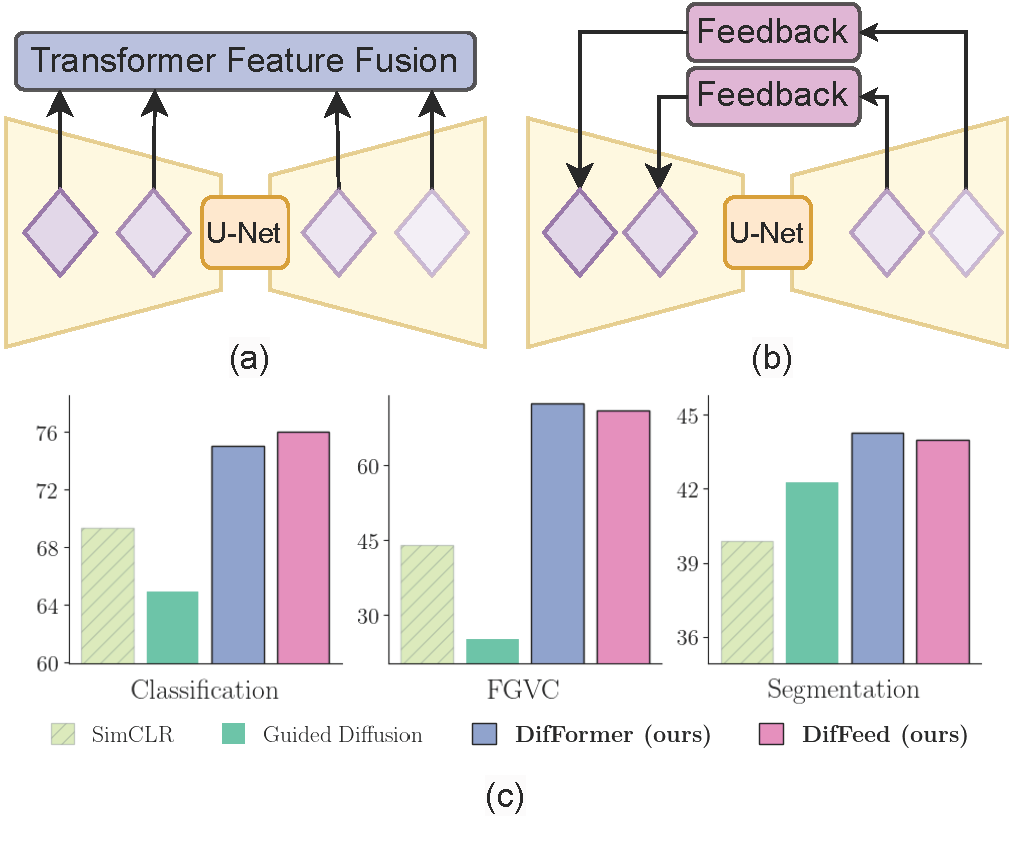
Soumik Mukhopadhyay*, Matthew Gwilliam*, Yosuke Yamaguchi✝, Vatsal Agarwal✝, Namitha Padmanabhan, Archana Swaminathan, Tianyi Zhou, Abhinav Shrivastava European Conference on Computer Vision (ECCV), 2024 Project Page | Paper | Code Explore diffusion models as unified unsupervised image representation learning models for many recognition tasks. Propose DifFormer and DifFeed, novel mechanisms for fusing diffusion features for image classification. |
|
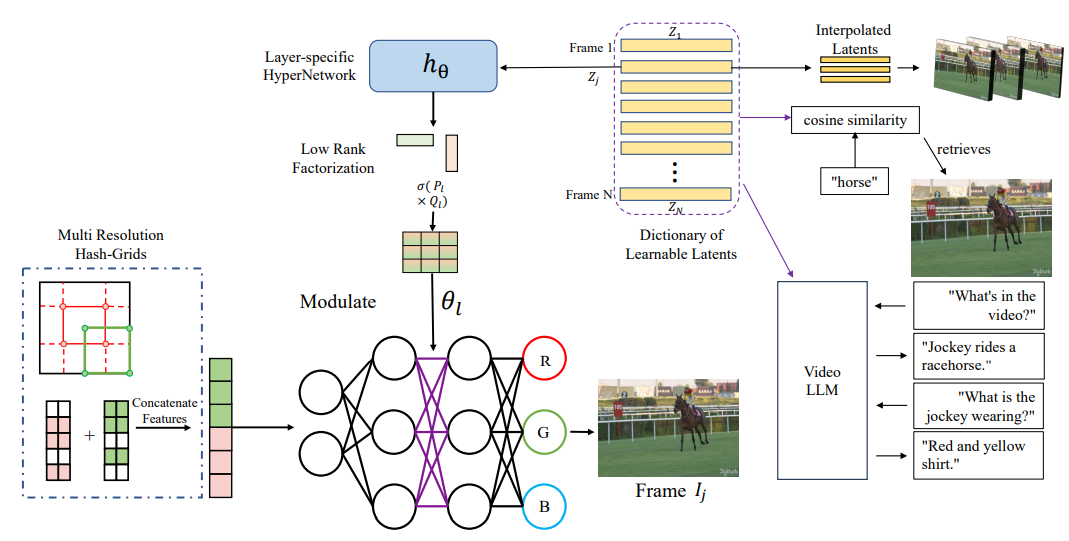
Shishira R Maiya*, Anubhav Gupta*, Matthew Gwilliam, Max Ehrlich, Abhinav Shrivastava European Conference on Computer Vision (ECCV), 2024 Project Page | Paper Develop implicit neural video models that perform well not only for compression, but also for retrieval, chat, and more. |
|
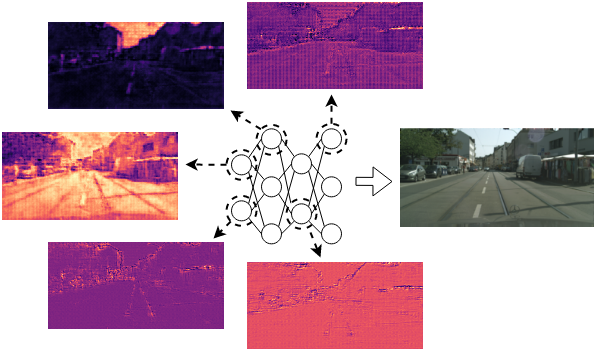
Namitha Padmanabhan*, Matthew Gwilliam*, Pulkit Kumar, Shishira Maiya, Max Ehrlich, Abhinav Shrivastava IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024 Project Page | Paper | Code XINC dissects Implicit Neural Representation (INR) models to understand how neurons represent images and videos and to reveal the inner workings of INRs. |
|
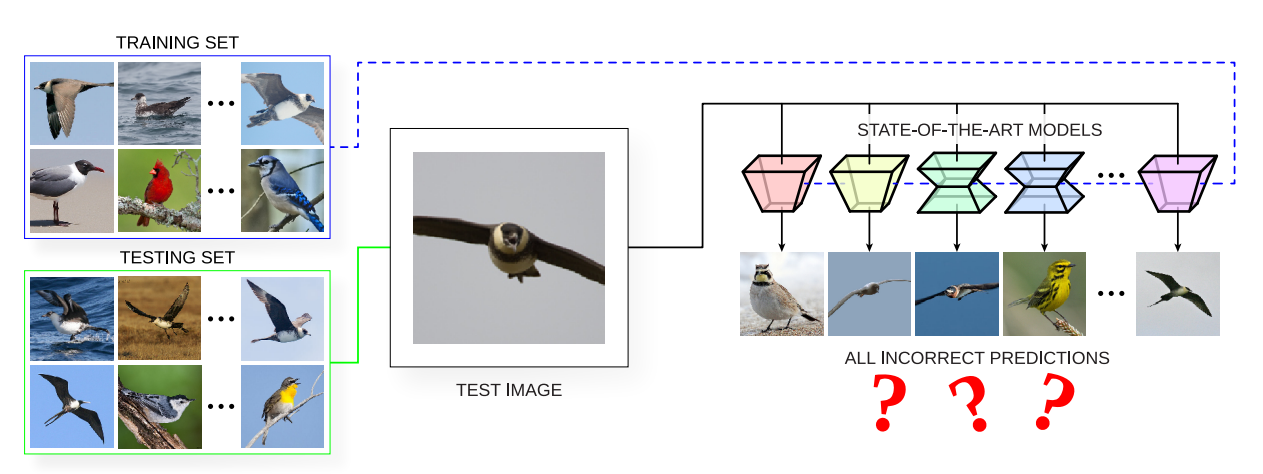
Connor Anderson Matthew Gwilliam, Evelyn Gaskin Ryan Farrell IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024 Paper Identify error types and image difficulty among state-of-the-art models for fine-grained visual categorization. |
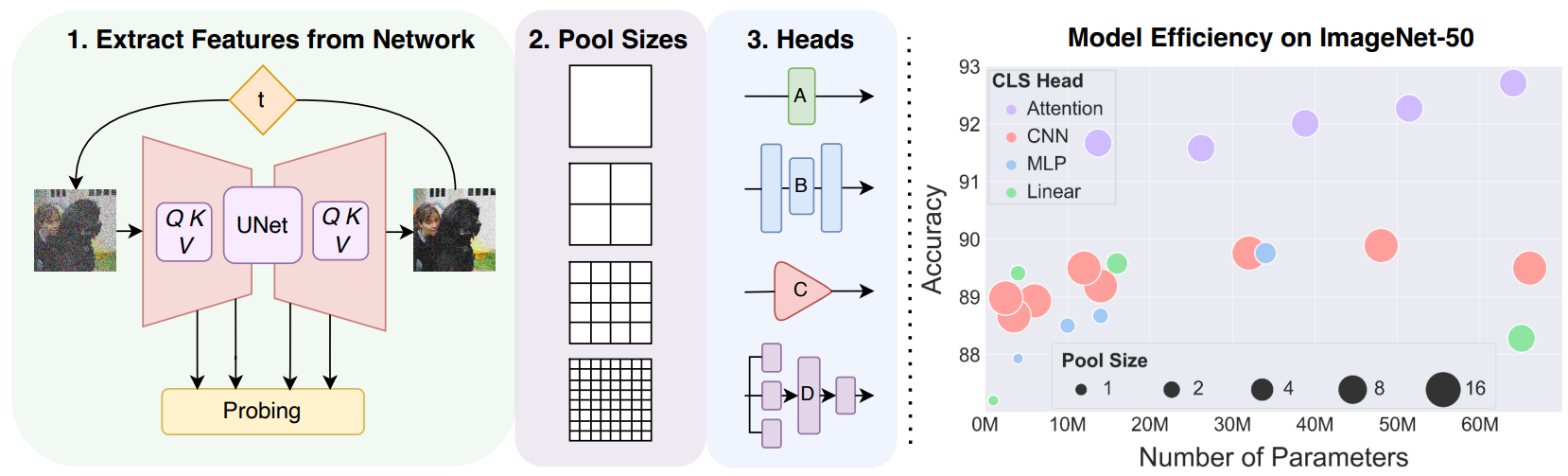
|
Soumik Mukhopadhyay*, Matthew Gwilliam*, Vatsal Agarwal, Namitha Padmanabhan, Archana Swaminathan, Tianyi Zhou, Abhinav Shrivastava Preprint only Project Page | Paper Show the potential of diffusion models as unified unsupervised image representation learners. |
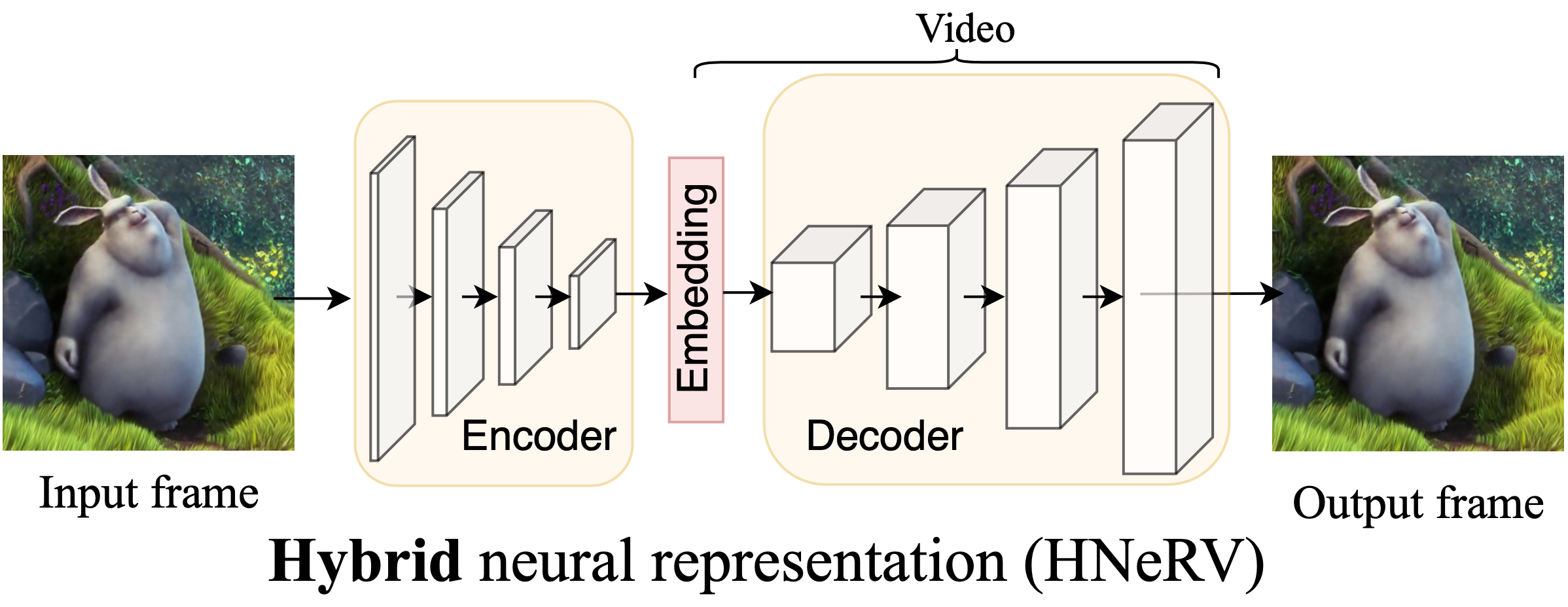
|
Hao Chen, Matthew Gwilliam, Ser-Nam Lim, Abhinav Shrivastava IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023 Project Page | Paper | Code Combine the strengths of implicit (NeRV) and explicit (autoencoder) representation to create a hybrid neural representation for video with good properties for representation, compression, and editing. |
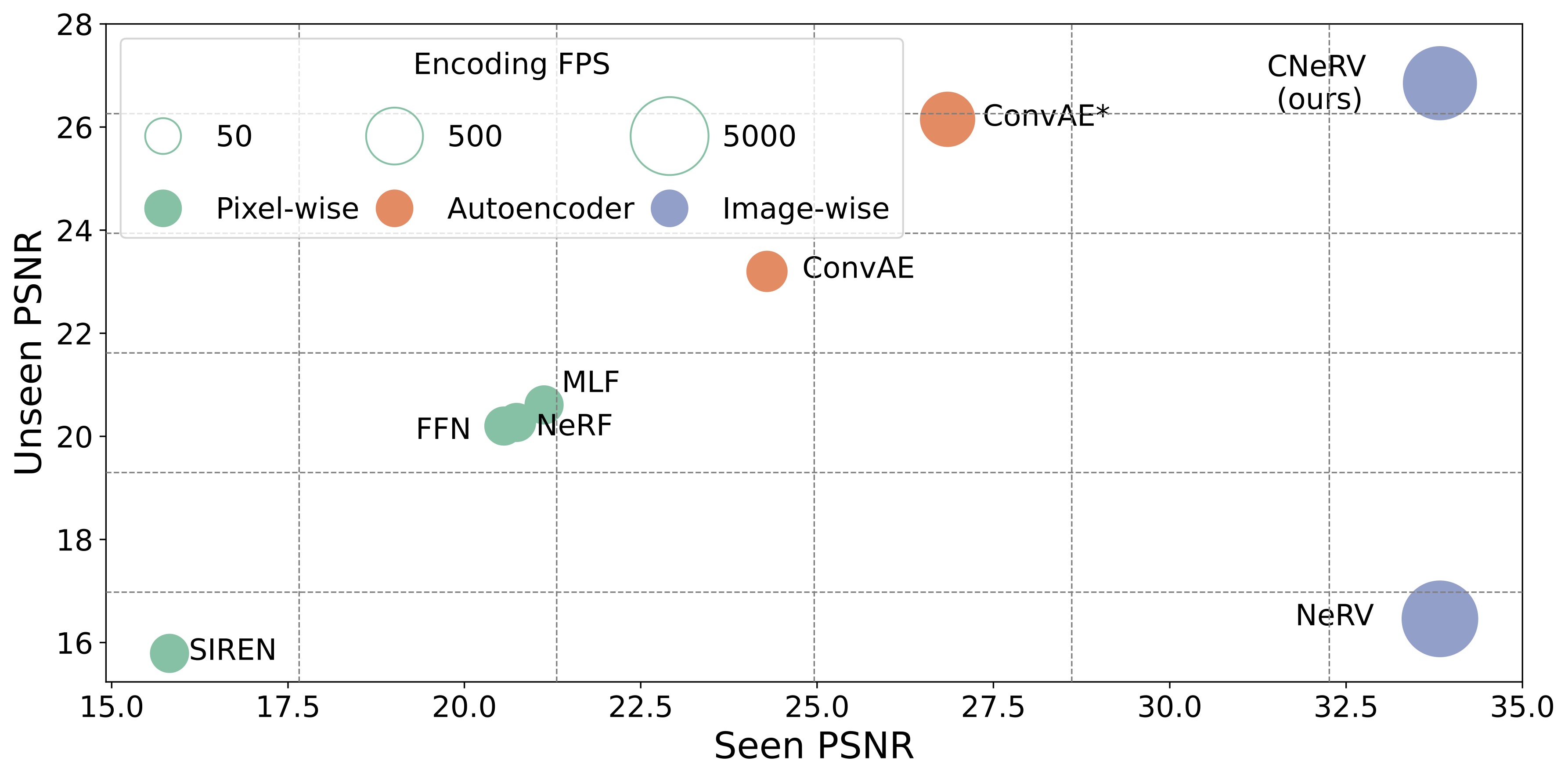
|
Hao Chen, Matthew Gwilliam, Bo He, Ser-Nam Lim, Abhinav Shrivastava British Machine Vision Conference (BMVC), 2022 (ORAL) Project Page | Paper Make implicit video representation networks generalize to unseen data by swapping time embedding for content-aware embedding that is computed as a unique summary of each frame. |
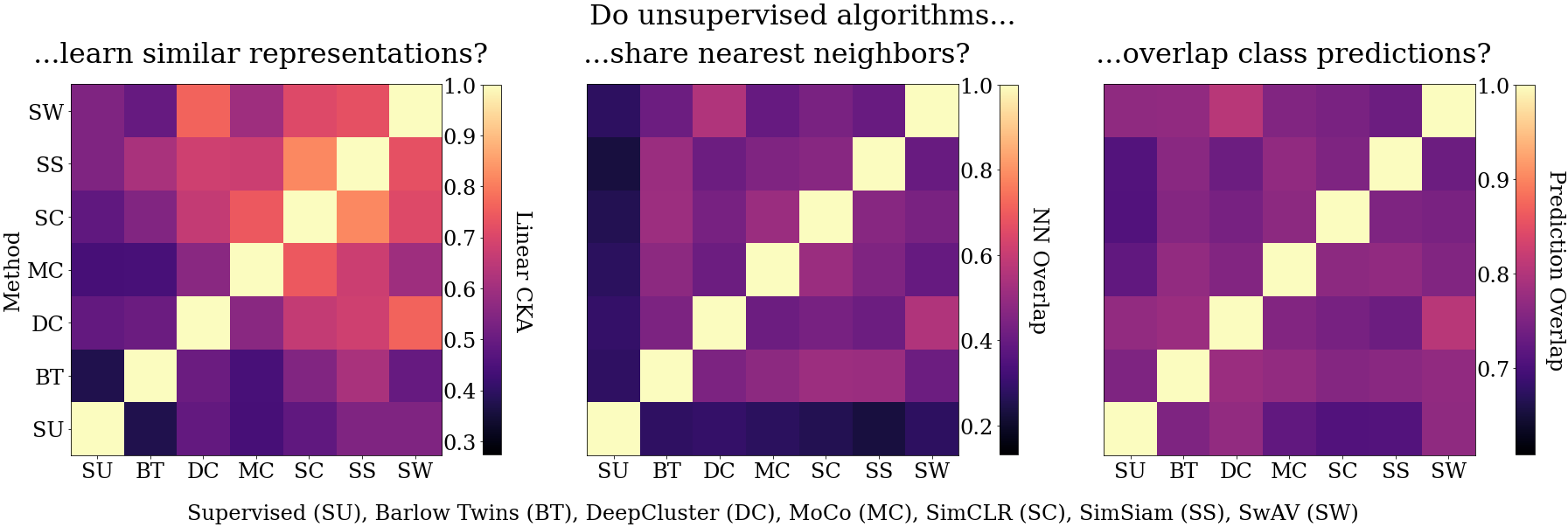
|
Matthew Gwilliam, Abhinav Shrivastava IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022 Project Page | Paper | Code Examine, compare, and contrast popular unsupervised image representation learning methods, showing that there are significant differences based on specific algorithm used, and "supervised vs. unsupervised" comparisons which neglect these differences tend to over-generalize. |
|
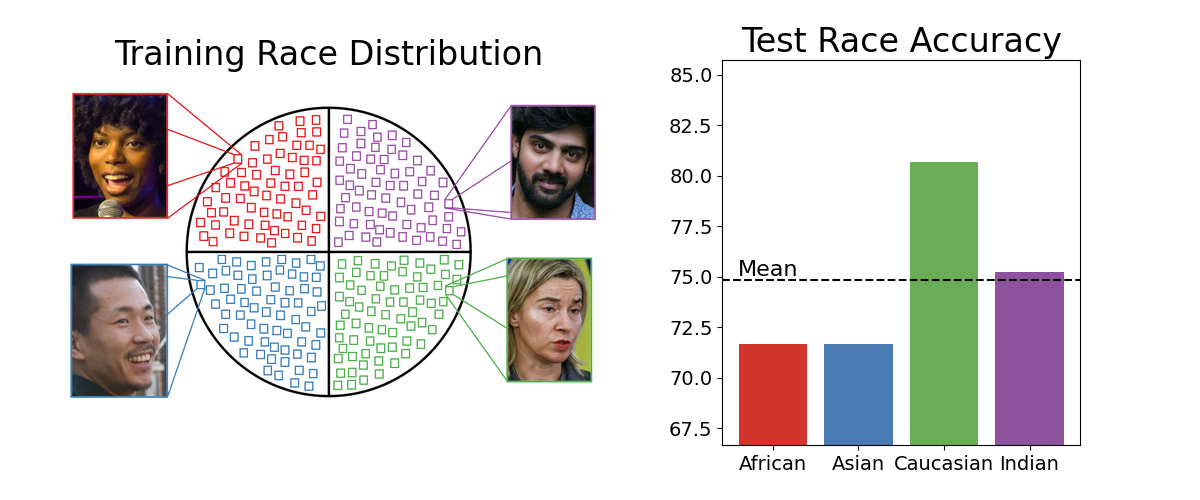
Matthew Gwilliam, Srinidhi Hegde Lade Tinubu Alex Hanson IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), 2021 Paper | Code Reveal the role of data in racial bias for facial recognition systems, and the flaws underlying the assumption that balanced data results in fair performance. |
|
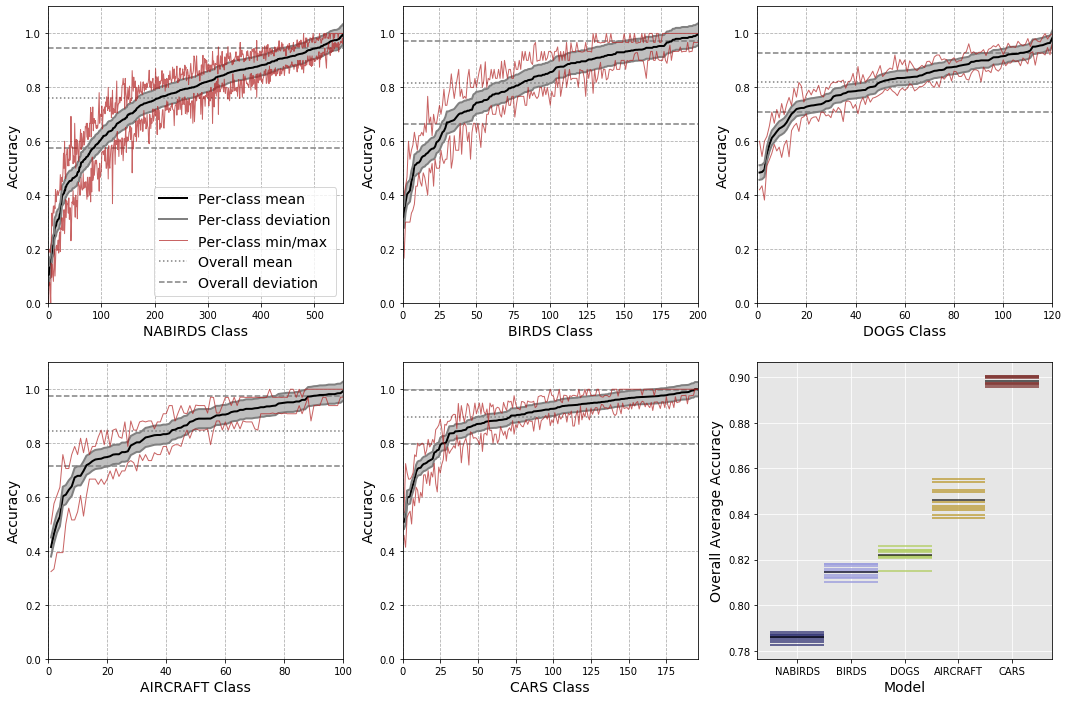
Matthew Gwilliam, Adam Teuscher Connor Anderson Ryan Farrell IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2021 Paper Uncover the large, often-ignored amount of variance in FGVC systems across training runs, on the dataset level, but more particularly in terms of the classification performance for individual classes. |
|
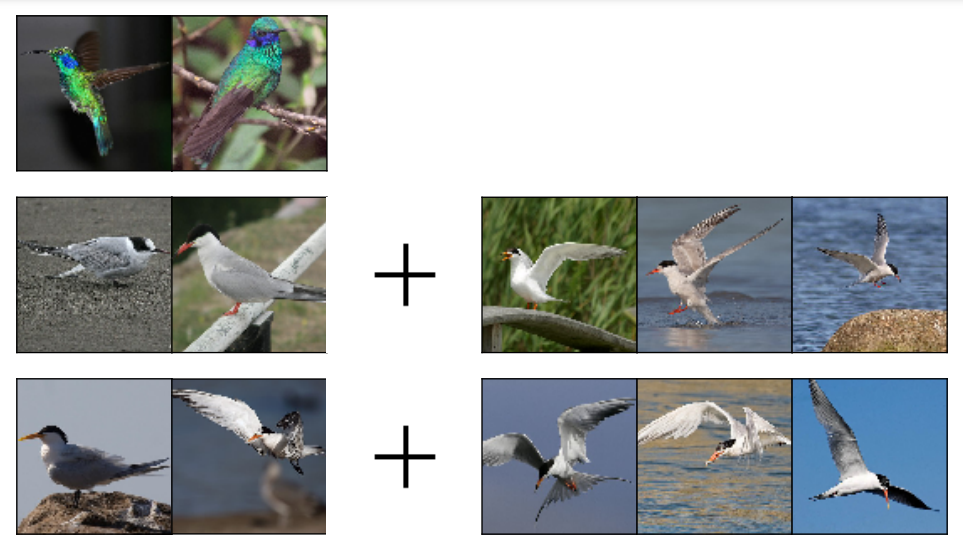
Matthew Gwilliam, Ryan Farrell IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2020 Paper Propose smart practices to optimize image curation, such that classification accuracy is maximized for a given constrained dataset size. |
|
|